Pyspark Connect To Postgresql
Before diving into the details, let’s gain a basic understanding of PySpark and PostgreSQL.
PySpark: PySpark is the Python library that enables the interaction between Python and Apache Spark. Apache Spark is a fast and general-purpose cluster computing system that provides an interface for distributed data processing. PySpark allows data scientists and analysts to leverage the power of Spark’s distributed computing capabilities using Python, a popular programming language for data analysis and machine learning.
PostgreSQL: PostgreSQL, also known as Postgres, is a powerful open-source object-relational database management system. It provides robust features, extensibility, and performance to handle large amounts of data while ensuring data integrity and security. PostgreSQL supports various data types, advanced SQL queries, and supports transactions for reliable data processing.
Now, let’s discuss the steps to connect PySpark to PostgreSQL and perform various operations:
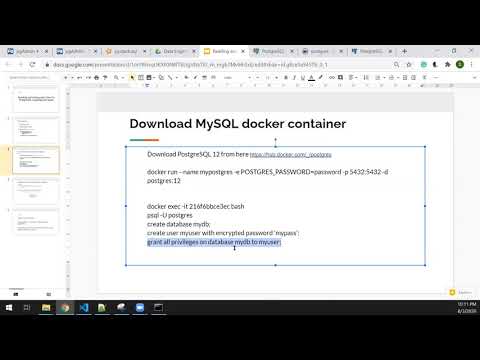
1. Setting up PostgreSQL database and tables:
– Install PostgreSQL: Download and install PostgreSQL from the official website (https://www.postgresql.org).
– Create a database: Use the PostgreSQL command line interface or a graphical tool like pgAdmin to create a database.
– Create tables: Define the tables and their schemas using SQL statements. You can use tools like pgAdmin or command line interfaces to execute these statements.
2. Installing and configuring necessary libraries:
– Install PySpark: Install PySpark using pip command or any other package manager.
– Install PostgreSQL JDBC driver: PySpark requires a JDBC driver to connect to PostgreSQL. Download the JDBC driver (PostgreSQL JDBC Driver) from the official PostgreSQL website or Maven repository.
– Configure the JDBC driver: Set the driver classpath in PySpark to let it know where to find the PostgreSQL JDBC driver.
3. Establishing the connection between PySpark and PostgreSQL:
– Import necessary modules: Import the required PySpark modules such as SparkSession and DataFrame.
– Create a SparkSession: Initialize a SparkSession that acts as an entry point to the PySpark application.
– Configure the PostgreSQL connection: Set the necessary connection properties such as database, hostname, port, username, password, etc.
– Establish the connection: Use the SparkSession object to establish a connection to the PostgreSQL database.
4. Performing basic operations on PostgreSQL tables using PySpark:
– Reading data: Read data from PostgreSQL tables using PySpark’s DataFrame API. You can use functions like `spark.read.jdbc()` to read specific tables or custom SQL queries.
– Writing data: Write data to PostgreSQL tables using PySpark’s DataFrame API. You can use functions like `DataFrame.write.jdbc()` to specify the target table and write mode (overwrite, append, etc.).
– Updating and deleting data: Execute update and delete operations on PostgreSQL tables using PySpark’s DataFrame API. You can use functions like `DataFrame.write.jdbc()` with appropriate delete or update queries.
5. Executing advanced queries and aggregations on PostgreSQL tables using PySpark:
– Specify custom SQL queries: Use PySpark’s DataFrame API to execute advanced SQL queries on PostgreSQL tables. You can use functions like `DataFrame.createOrReplaceTempView()` to register the DataFrame as a temporary table and then execute SQL queries using `spark.sql()` method.
– Perform aggregations: Perform complex aggregations on PostgreSQL tables using PySpark’s DataFrame API. You can use functions like `groupBy()`, `agg()`, and various aggregate functions to compute metrics and statistics.
6. Loading and writing data between PySpark and PostgreSQL:
– Loading data: Load data from other data sources into PySpark and write it to PostgreSQL tables. PySpark provides connectors for various data sources like CSV, JSON, Parquet, etc.
– Writing data: Export data from PostgreSQL tables into PySpark and perform further processing or analysis. You can use functions like `spark.read.jdbc()` to load specific tables or custom SQL queries.
Now, let’s address some frequently asked questions (FAQs) related to PySpark connecting to PostgreSQL:
Q1. How can I write data from PySpark to PostgreSQL?
To write data from PySpark to PostgreSQL, you can use the `DataFrame.write.jdbc()` function. It allows you to specify the target table, connection details, and write mode (overwrite, append, etc.). For example, you can use the following code to write a DataFrame to a PostgreSQL table:
“`
df.write.jdbc(url=’jdbc:postgresql://localhost/mydatabase’, table=’my_table’, mode=’overwrite’, properties={‘user’: ‘my_user’, ‘password’: ‘my_password’})
“`
Q2. Can I connect PySpark to a Microsoft SQL Server instead of PostgreSQL?
Yes, PySpark offers connectors to connect to various database systems, including Microsoft SQL Server. You can follow a similar process to establish a connection between PySpark and SQL Server by configuring the JDBC driver and connection properties accordingly.
Q3. How can I perform upsert (update or insert) operations on PostgreSQL tables using PySpark?
Currently, PySpark does not provide built-in support for upsert operations. However, you can achieve upsert functionality by using a combination of PySpark and PostgreSQL capabilities. One way is to read the PostgreSQL table as a PySpark DataFrame, perform the required transformations, and then write the data back to the table using a specific update or insert logic in the SQL query.
Q4. What is the PostgreSQL JDBC driver and how can I install it?
The PostgreSQL JDBC driver is a Java library that allows connectivity between Java applications (like PySpark) and PostgreSQL databases. You can download the JDBC driver from the official PostgreSQL website or Maven repository. After downloading, you can configure the driver classpath in PySpark to let it know where to find the driver.
Q5. Is there a specific connector for Spark and PostgreSQL?
Yes, the Spark ecosystem provides a dedicated connector called “Spark postgres connector” that enables efficient data transfer between Spark and PostgreSQL. The connector optimizes the data transfer process and provides additional features like parallelism, data partitioning, and batching. You can include this connector as a dependency in your PySpark application to leverage its capabilities.
Q6. I encountered a “classnotfoundexception org.postgresql.Driver” error while connecting PySpark to PostgreSQL. How can I resolve it?
This error occurs when the PostgreSQL JDBC driver is not properly configured or not available in the PySpark environment. Make sure you have downloaded the correct version of the JDBC driver and set the driver classpath correctly in PySpark. Additionally, check for typos or any syntax errors in the connection properties.
In conclusion, connecting PySpark to PostgreSQL opens up a wide range of possibilities for performing data processing and analysis on PostgreSQL tables using PySpark’s distributed computing capabilities. By following the steps mentioned above, you can establish the connection, perform basic and advanced operations, and load and write data between PySpark and PostgreSQL seamlessly. Remember to configure the necessary libraries, set up the database and tables, and understand the JDBC driver requirements to ensure a successful connection.
20200803 – Reading And Writing Data From/To Postgresql Using Apache Spark
How To Read Data From Postgres In Pyspark?
PySpark, the Python library for Apache Spark, is a powerful tool for big data processing and analytics. It provides a simple and efficient interface for working with large datasets and offers built-in support for various data sources, including PostgreSQL.
Reading data from PostgreSQL into PySpark allows you to leverage the advanced data manipulation and analytics capabilities of PySpark on your PostgreSQL database. In this article, we will explore how to read data from PostgreSQL in PySpark and examine some frequently asked questions.
Step 1: Set up the Environment
Before we start reading data from PostgreSQL, we need to ensure the necessary environment is set up. Here are a few requirements:
1. Install PySpark: PySpark can be installed using Python’s package manager, pip. Simply run the command `pip install pyspark` to install it.
2. Install psycopg2: Psycopg2 is a PostgreSQL adapter for Python. It enables us to connect to a PostgreSQL database and execute SQL queries. Install it using the command `pip install psycopg2`.
3. Set up a PostgreSQL database: Ensure that you have a running instance of PostgreSQL with a database and table(s) containing the data you want to read.
Step 2: Connect to the PostgreSQL Database
To read data from PostgreSQL in PySpark, we first need to establish a connection to the database. PySpark provides the `pyspark.sql` module for interacting with structured data sources.
Start by importing the necessary libraries:
“`python
from pyspark.sql import SparkSession
“`
Next, create a SparkSession object, which is the entry point to any PySpark functionality:
“`python
spark = SparkSession.builder \
.appName(“Read PostgreSQL with PySpark”) \
.getOrCreate()
“`
The `”Read PostgreSQL with PySpark”` is the name of the Spark application. You can name it according to your preference.
Step 3: Reading Data from PostgreSQL
With the connection established, we can now read data from PostgreSQL by loading the table(s) as DataFrame(s). A DataFrame is a distributed collection of data organized into named columns.
To load a table as a DataFrame, use the `spark.read` method:
“`python
dataframe = spark.read \
.format(“jdbc”) \
.option(“url”, “jdbc:postgresql://
.option(“dbtable”, “






 from Cloud DataProc | PySpark Job - Google Cloud Platform - YouTube")
















